Getting Started with the Flickr API:
911 images have been cataloged via a python script that repeatedly hits the Flickr API and inserts photos matching the search term "campsite" into a PostGIS table. It turns out that many are outside of the US and wouldn't be of interest to The Dyrt team. But PostGIS can quickly select the photos that are taken within the US:
SELECT * FROM photos p INNER JOIN states s ON ST_Intersects(p.geog, s.geog)
This reduces the number of photos to 467. Many of these are of campsites, such as this one and this one. But many other photos are not entirely relevant. More tomorrow.
Amazon Rekognition
Amazon Rekognition is showing a lot of promise to identify objects that can indicate that a photo is actually a taken at a campsite as opposed to a hike near a campsite:
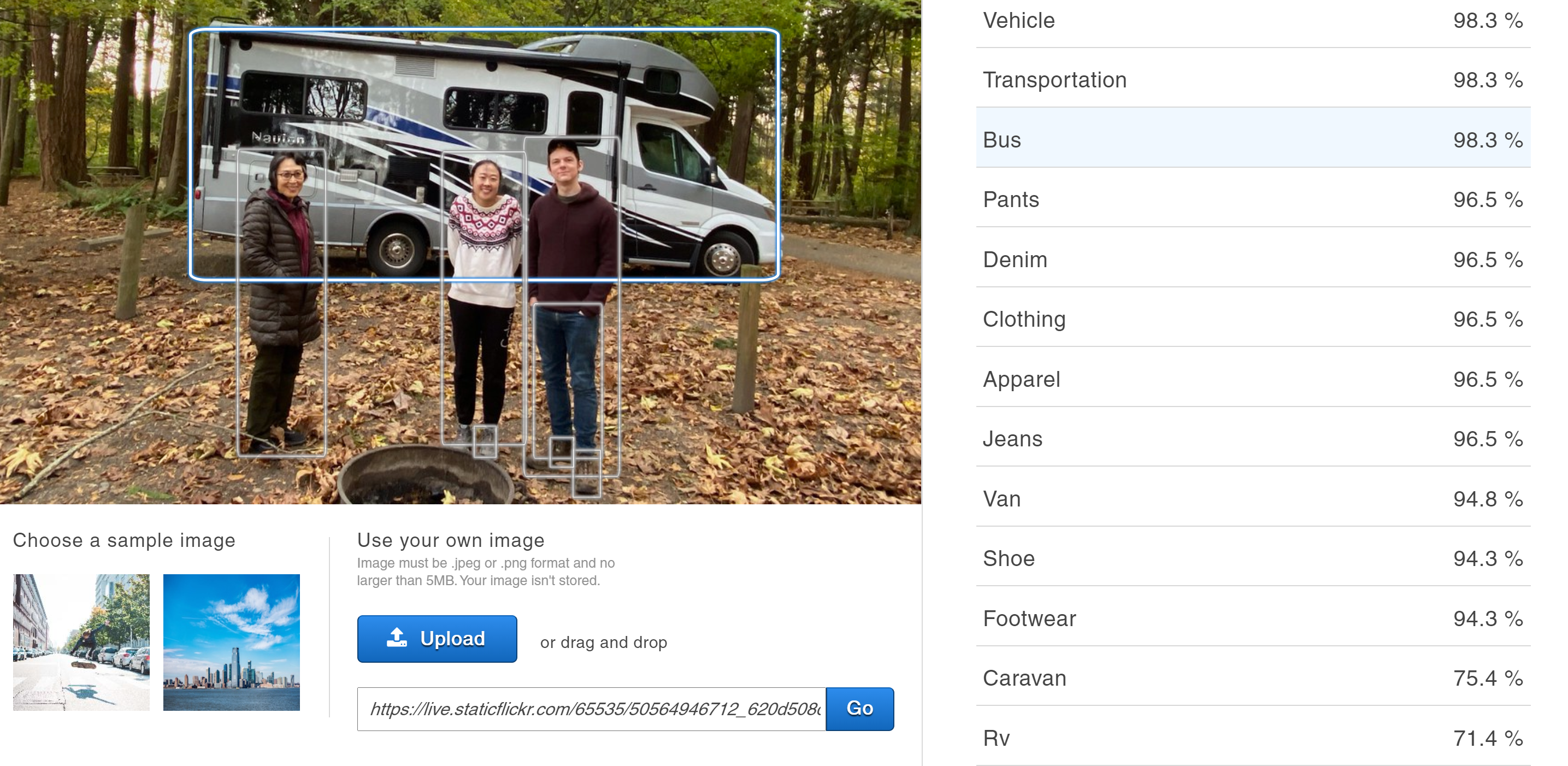

{kind=link}
{kind=link}
There are a number of Python scripts on the internet that show how you can upload an image to Rekcognition and then extract that labels that the service outputs.
Geotagged photo count now over 92,000!
I was really doubting that there were only ~900 geotagged flickr photos that matched the search terms “campground” and “campsite”. Some Googling led me to this post on the flickr forums from 11 years ago. A flickr staff member noted that “the flickr.photos.search function doesn't not return more than 4000 photos for a single search.” It’s very unfortunate that this is not mentioned in the documentation. But as suggested, I started querying the API in three-month chunks starting with January 1, 2000. I figured that photos more than 20 years old may contain information that is outdated.
We can run the same query that I posted earlier to determine how many of them are in the US: 53,152. While spatial databases can perform spatial queries ‘on the fly’, those queries can be quite expensive when very large geometries, such the boundaries of each state, are involved. So let’s update let’s populate the state field on the photos table:
UPDATE photos SET state = (SELECT states.name FROM states WHERE st_intersects(photos.geog, states.geog));
Now we can quickly count the number of photos from each state and determine which states have the most photos:
SELECT state, count(*) AS photoCount
FROM photos
GROUP BY state ORDER BY photoCount DESC
The first several rows of results:
|
California |
11910 |
|
Washington |
3581 |
|
Arizona |
3245 |
|
Oregon |
2749 |
|
Michigan |
2176 |
|
Utah |
2142 |
|
Florida |
2134 |
|
Colorado |
2105 |
Being a large state with tons of public land, it’s not surprising to see that California came out on top. This analysis can also be used to uncover errors in The Dyrt's database, such as this campsite outside of Crested Butte, Colorado that is listed as being in South Dakota.
Finding Probable Campsites
I downloaded point locations matching tourism=camp_site and tourism=caravan_site from Open Street Map. If we pretend that those Open Street Map locations are the campground locations in The Dyrt’s database, how can we tell if the Flickr photos that we acquired from their API includes campgrounds or campsites that The Dyrt hasn’t inventoried? This query returns a list of the closest Flickr photo to the closest OSM (The Dyrt) campground, along with the distance between them.
SELECT
photos.flickr_id,
osm_points.osm_id,
osm_points.dist
FROM photos
CROSS JOIN LATERAL
(SELECT
planet_osm_point2.osm_id as osm_id,
ST_Distance(planet_osm_point2.way, photos.geog) as dist
FROM planet_osm_point2
WHERE planet_osm_point2.tourism = 'camp_site' and photos.search_term = 'text=''campsite'''
ORDER BY photos.geog planet_osm_point2.way
LIMIT 1) AS osm_points
Any Flickr photo location that’s far from the OSM point could be a new campground or campsite. This CSV file lists a few probable dispersed campsites that don’t appear to be listed on The Dyrt website.
Finding Potential Duplicate Campsites in the Dyrt Database Using Spatial Searches
In this hypothetical situation, let’s pretend that my database of Flickr photos is The Dyrt’s database of campgrounds. Points that are close to each other probably indicate duplicate Campgrounds. They can be revealed using the following query that lists the closest point to each point, as well as the distance between them:
SELECT p1.id AS p1_id,
p2.id AS p2_id,
ST_Distance(p1.geog, p2.geog) AS dist
FROM photos AS p1
CROSS JOIN LATERAL (
SELECT id,
geog
FROM photos
WHERE p1.id id
ORDER BY
p1.geog geog
LIMIT 1
) AS p2
;
Then staff at The Dyrt could review campgrounds that are below a certain distance threshold, such as a kilometer. For example, these three campgrounds appear to be duplicates:
-- Olallie on McKenzie Highway
-- Willamette National Forest Olallie Campground
-- Olallie Campground
Mining Online Reviews to Extract Information about Campgrounds
I combed an online review API to gather over 10,691 reviews of 2,354 campgrounds in the Southeast and Mid-Atlantic regions. Once these reviews were in a database, you can start trying to extract campground amenities with a simple SQL statement with wildcards.
SELECT campground_id, review_text FROM reviews WHERE review_text LIKE ‘%showers%’
But there are problems with this approach. First, using wildcards on the front of a string makes it impossible for the database to use basic types of indexes. The second problem is that it won’t find the singular word ‘shower’. To get around these problems, you could use full text indexing. In PostgreSQL, you can apply an index on the review text using the to_tsvector() to extract and index lexemes. Doing so eliminates the two problems mentioned earlier.
But other problems remain. What if the review states that “there are no showers”? Using a PostgreSQL query like “WHERE to_tsquery(‘shower’)” will not detect that the reviewer was stating that showers are NOT available. But natural language processing (NLP) tools can definitely help here.
SpaCy has a huge number of NLP tool. Let’s use its pattern matching features here:
# create a list of amenity words
list_words = ['shower', 'picnic table','mountain biking', 'playground', 'swimming pool','dump station','firewood', 'fire ring','firering'
'wifi', 'sewer hookup', 'water hookup', 'tent site', 'flush toilet', 'pit toilet', 'electric hookup','disc golf', 'fishing','pavillion',
'phone service', 'Sanitary Dump']
#build a matcher
patterns = [nlp(text) for text in list_words]
matcher = PhraseMatcher(nlp.vocab, attr="LEMMA")
matcher.add("myAmenityMatcher", None, *patterns)
spacy_doc = nlp(row[1])
matches = matcher(spacy_doc)
for match_id, start, end in matches:
# loop through the matches
string_id = nlp.vocab.strings[match_id]
span = spacy_doc[start:end] # The matched span
previous_word = spacy_doc[start -1: start]
if previous_word.lemma_ == 'no':
#the previous word is ‘no’ or ‘No’ or ‘NO’
no_keywords.append(span.text)
else:
keywords.append(span.text)
In the above code, SpaCy is finding our amenity keywords, but it is also extracting the word (token) preceding our amenity keyword. If that word has the lemma of ‘no’, then we add it an array of amenities that are probably absent from the campground. Otherwise, we add it to an array that lists amenities that are probably at the campground. These arrays can them be stored in a database that lists campground amenities.
While detecting the word “no” before one of the amenities is helpful, what happens when a reviewer writes, “This campground does not have showers or potable water”? SpaCy can used to extract parts of speech and word dependencies, as shown below.

“Showers” and “potable water” are identified as direct objects. And, more importantly, “not” is identified as a negation. These amenities can then be flagged as probably absent at a campground.